医療ビッグデータ、その課題~DPCを中心に
経済・ビジネス 科学 技術・デジタル 社会 文化- English
- 日本語
- 简体字
- 繁體字
- Français
- Español
- العربية
- Русский
超高齢社会への対処に活用待ったなし
夜更けのコンビニエンスストア。レジの店員がお客をちらっと見て、「30~49歳・男性」と書かれたボタンを押した後、ピッピッと「角煮まん、ウーロン茶ペットボトル500mL」と商品のバーコードを読み取る。そのデータは、POS(販売時点情報管理)システムを介して即座に本部のホストコンピューターに入り、日々蓄積されて、各店舗の仕入れや新商品の開発に活かされる。このようなビッグデータを活かしたマーケティングへの活用や経営管理は、世界に先駆け、1980年代に日本のコンビニに導入された。
「コンビニエンスな」学生生活を過ごした私は、日々行われる医療行為についてもデータ収集と分析が進めば、コスト・アクセス・質を同時に達成するという医療界の最大の難題についても最適解が導かれ、憂いのない老後を送れるのではないかと漠然と思っていた。しかし、こと人の生死にかかわる究極の個人データである医療情報においては、道はそう平たんではなかった。しかし、団塊の世代が後期高齢者入りして日本の社会保障が最大の試練を迎える2025年に向け、ビッグデータ活用は待ったなしだ。
医療現場はビッグデータの宝庫
医療現場こそは、Volume(量)、Velocity(速度)、Variety(種類)で特徴付けられるビッグデータの宝庫だ。患者調査(2011年度、厚生労働省)によれば、日本全体の1日あたりの患者数は入院が約134万人、外来が約726万人。それぞれが手術、薬、処置など、個々の疾病に応じて多種多様なサービスを受ける“多品種少量生産”が当たり前の世界だ。
その診療情報の内訳は、医療機関(病院、診療所、薬局)が、医療費の公的保険負担分の支払いを審査支払機関に求める際のレセプト(診療報酬明細書)に明記されるが、これを電子化するだけでも大騒ぎだった。2006年ごろまでには、医療機関の大半はコンピューターでレセプトのデータを管理していたが、それを紙に出力して送付するため、1年間で14億枚、富士山の倍の高さにも積み重なった。受け取った基金の側は、それをOCRで読み取って電子化した。それが同年の厚生労働省令で、ようやく2011年からレセプトの電子化・オンライン請求が、原則義務化されることになった。
2009年以降、電子化されたレセプト情報は、「ナショナル・データベース」(NDB)として、国がすべて保存しており、解析次第で、ビッグデータの4つ目のVである Value(価値)を生み出すことができるが、その取り組みはまだ緒に就いたばかりだ。
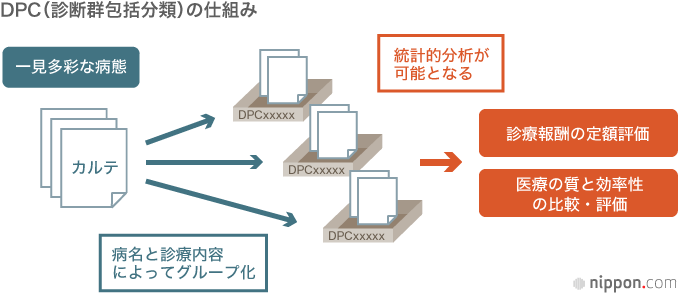
DPC(診断群包括分類)データの蓄積、質向上・効率化に寄与
一方、一歩先んじて、医療の質や効率化に寄与しているビッグデータが、DPC(診断群包括分類)に基づく診療情報のデータで、今ではNDBにも含められている。DPCとは、「Diagnosis Procedure Combination」の略で、Diagnosis(診断)とProcedure(治療・処置)のCombination(組み合わせ)。入院したことのある人であれば、既にこの方式で支払いをしている可能性が高い。
日本の医療は、投入した医療資源をすべて請求する「出来高払い」が基本で、過剰診療を招くとの批判も大きかった。このため「包括払い」が模索され、1日当たりの値付けがなされたが、この単価のための分類がDPCである。2003年に82の特定機能病院(大学病院の本院など)にDPCによる1日当たり定額の支払い方式が導入されて後、手挙げ方式で徐々に導入病院が拡大し、2014年度には、主として急性期医療を中心とする約 1860の病院が参加もしくは準備中で、全国90万床余りの一般病床(主として急性期の患者を対象)の約59%に当たる53万床をカバーしており、年間800万件を超えるデータが蓄積されている。
そもそも包括払いは、青天井の医療費にキャップをはめようという意図があり、DPCによる包括払い(1日当たり単価は入院日数に応じて段階的に減額)が、医療費削減に資することは納得できる。実際に、OECD諸国の中でも突出して長かった日本の在院日数の短縮などにも寄与している。
しかも、DPCは構造化されたデータであるため、さらなるValueが生み出される。
診療実績など病院間の比較が可能に
DPCコードは14桁からなり、入院期間中に医療資源を最も投入した傷病名(約2500分類)に加え、年齢・体重・意識障害レベル、手術や処置の種類、使用薬剤、医療資源の投入量に影響を与えるような合併症や重症度が、すべて数値化されて盛り込まれている(下図)。これに在院日数、費用などの情報も加えたデータセットによれば、医療情報を透明化できるようになる
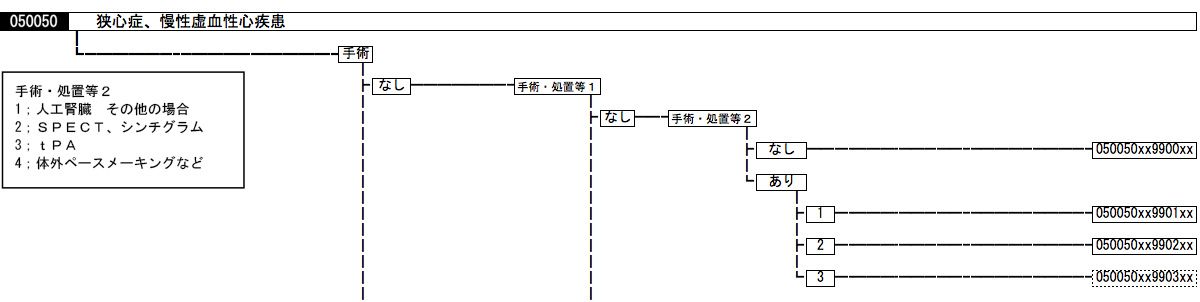
実は、診断群で先行していた米国には、1970年代初頭にイェール大学で開発されたDRG(Diagnosis Related Groups)という診断分類があり、3M(スリーエム)が商品として販売していた。それを“直輸入”して米の配下に入ることなく、より精緻化した日本独自のDPCを開発し、50万床レベルで収集しているのは、世界的にも誇れることである。
各病院から提出されたDPCデータは厚労省で集計され、年1回、「DPC導入の影響評価に関する調査」として、病院名入りで公開されている。
診療情報を積み上げただけのレセプト・データでは、診療行為ごとの回数や処方薬剤の量などの質的な分析であれば容易にできるが、一手間かけたDPCデータによって、医療の全体像を把握できるだけでなく、同じ病名であっても医療機関によって診療内容にバラツキがあることが一目瞭然に分かってくる。
患者・住民は、自分がかかっている疾患について、どういう病院がどのような診療を行っているかが、入院期間や医療費も含めて知ることもできる。DPCごとの月平均退院患者数、医療圏シェア、平均在院日数などの診療実績の比較もできる。厚労省が提供しているのは、Excelで集計した生データなので、非常に見づらいが、一覧性を高め、検索機能などを付加した民間のDPCデータに基づく病院比較サイトもある。
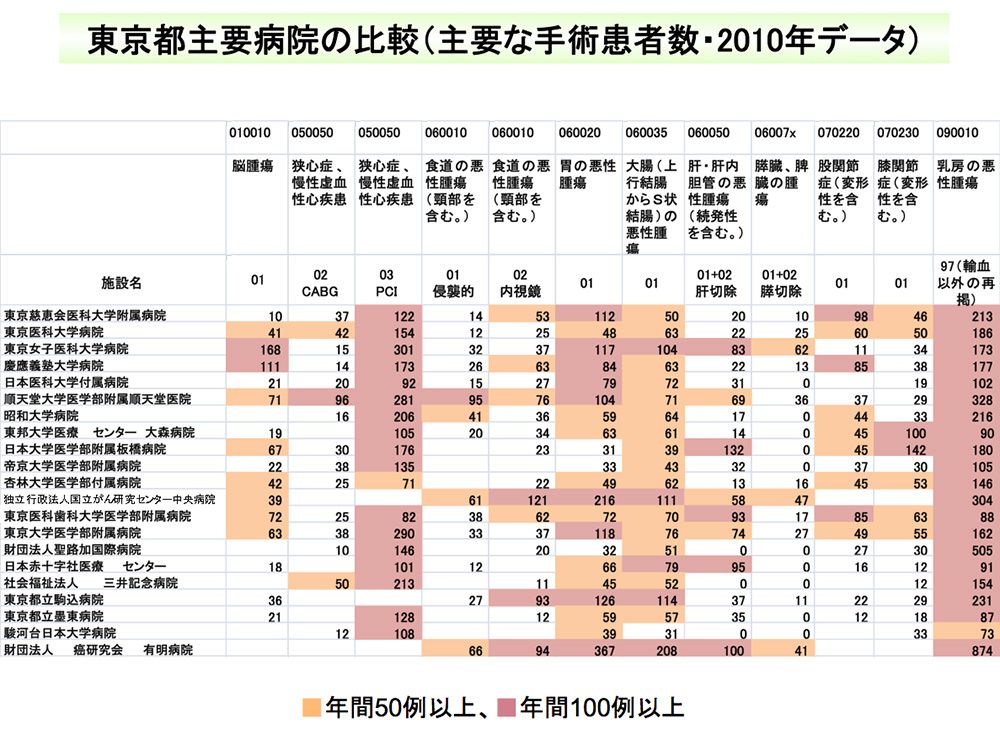 DPCデータを基に作成した、東京都の特定機能病院の手術実績比較
DPCデータを基に作成した、東京都の特定機能病院の手術実績比較
質に踏み込んだ分析で、医療機関の淘汰も?
医療分野のデータサイエンティストがこれを分析すると、さらに医療の質にまで踏み込んだ分析ができる。例えば、ガイドラインにのっとった治療を行っているか、入院中に合併症が発生していないかなども分かる。がん治療などは新薬の開発も盛んな領域であるが、旧態依然とした治療を行っている病院も明らかになり、日本の治療の標準化を促すこともできる。
DPCデータは、マクロでは、適切な診療報酬体系や地域医療計画などの構築の拠り所とできるものであり、ミクロでは、各病院がこのデータをベンチマークにして自院の質向上やマーケティングに活かすことができる。
将来は、医療の質に基づく支払い(Pay for performance: P4P)とDPCとを連動させることも検討されているが、これはかなり議論を呼びそうだ。ただし、DPCによる医療実績の公開が進めば、医療の質を維持できない病院は撤退を迫られることにもなりかねない。
転院ではデータ途切れ、患者の追跡できず
さて、日本の医療が抱える最大の課題である効率化という点を考えた場合、DPCが対象とする入院医療だけでなく外来医療もあり、主として開業医らが担っている部分にもメスを入れないと、トータルで医療費の効率化につながらない。しかし、入院外の医療は生死に直結するものは少なく、慢性期医療という位置付けである。
 東京医科歯科大学の伏見清秀教授
東京医科歯科大学の伏見清秀教授
「医療費抑制のメーンターゲットは入院医療。外来の医療費は診療単価だけでコントロールできる」と語るのは、東京医科歯科大学医歯学総合研究科医療政策情報学分野教授の伏見清秀氏。医療費の一定額を保険対象から除外し、患者負担とする保険免責制を入れるという方法もあるという。
伏見氏は、日本におけるDPC制度の導入から現在に至るまで、その制度運営を学術的にサポートしてきた立場から、DPCデータを本格的に活用するには、まだ環境の不備があると指摘する。その最大の課題が、患者の追跡ができない不自由さだ。
DPCデータは病院単位で提出するデータなので、ある病院に入院中の患者は把握できる。しかし、例えば、ある治療の効果は、受けた患者を追跡し1カ月後に治っていたのか、あるいは死亡したのか、転院していたのかなどを把握しなくては検証しきれない。個人レベルの情報でありながら、個人情報を含まない複数のデータを個人単位でひも付けできることが重要なのだ。
ちなみに、コンビニは、レジでプロフィールを登録してもらい、ポイントカードを発行して自チェーン内では、購買データのひも付けを進めている。もちろん、医学研究における重要性は、その比ではなく、伏見氏は「日本の診療情報データが他のデータとつながらないのは歴史的汚点で、国益を損ねている」とまで言い切る。
マイナンバー、本人同意で医療に応用も検討か
研究においてビッグデータを解析する目的は定量的、定性的に仮説を検証するためで、年齢や性別は必要でも、個人を特定する必要はない。適切な個人識別番号によって、データが関連付けられれば良いが、そのハードルが高い。
社会保障・税番号(マイナンバー)により、年金などの社会保障と納税1つの個人番号で管理する制度が2016年にもスタートする。いわゆる国民総背番号制がようやく実現するが、これだけでもセキュリティー、プライバシー保護の2点について不安を呈する声が上がっているのに、さらにマイナンパーを病歴とつなげることには慎重論が恨強い。厚労省や日本医師会では別途、医療や介護のための医療IDの検討を進めていた。
政府は、マイナンバーを医療にも応用する方向で、本人が同意すれば医療機関や介護施設が個人の医療情報を共有できるようにする方針を固めているとされる。また、個人を特定できないデータは、本人の同意がなくても第三者に提供できるようにする個人情報保護法の改正案が、2015年度の通常国会にも提出されるという。
マイナンバーであれ医療IDであれ、これが健康保険と連動されれば、健康診断やカルテの情報など、自分の健康データが生涯を通じて管理でき、重複する検査や投薬なども減らせる。レセプトや DPCなどの NDBを用いた研究できるようになれば、その施策への応用も前進する。さらに、本稿では詳述しなかったが、医療には遺伝子情報というビッグデータもあり、これを活用できるようになれば、ゲノム創薬や個別化医療にも役立てる ことができる。どれもこれも逼迫(ひっぱく)する医療財政にとってプラスになるだろう。
施策の評価・検証にこそデータ活用を
最後は、コンビニの話に戻ろう。当然ながら、POS導入は米国で先行して普及していた。しかし、その目的はレジの打ち間違いや不正防止だったのに対し、POSデータをマーケティングに活用しようとしたのが、元々は米国で発祥した会社の子会社だった日本のセブンイレブン・ジャパンだ。
同社のPOSデータの使い方は、徹底した「仮説—検証型」であることでも知られる。つまり、単に売れているからそれを発注するといったレベルではなく、天候や立地など様々な条件から、自ら仮説を立てて発注し、売り方にも工夫を凝らした商品が、本当に売れたかどうかを確認するためにPOSデータを使うのである。医療においても、単に量的規制や健康保険の対象から外すといった目的だけに診療情報のビッグデータを使うのでなく、その後の施策の検証までをきっちり行うよう望みたい。